Understanding Failures and Mitigation Strategies in RAG Pipelines

In the previous post, we have built two baseline RAG pipelines, one local and one using a cloud-based LLM and embedding model. Now, we dive into an essential topic: understanding how these pipelines can fail.
Why is this important? If you're using RAG systems to provide information-rich responses, ensuring robustness is key to delivering a good customer experience. Understanding the potential failure modes in RAG pipelines allows you to take proactive measures to prevent or detect these issues, ultimately improving the reliability and quality of your system.
In this post, we will explore common failure modes by going through the pipeline from the ingestion phase up to the synthesis/generation phase, see figure 1. This knowledge sets the stage for our next posts, where we will discuss evaluation metrics and advanced techniques to enhance your RAG pipelines.
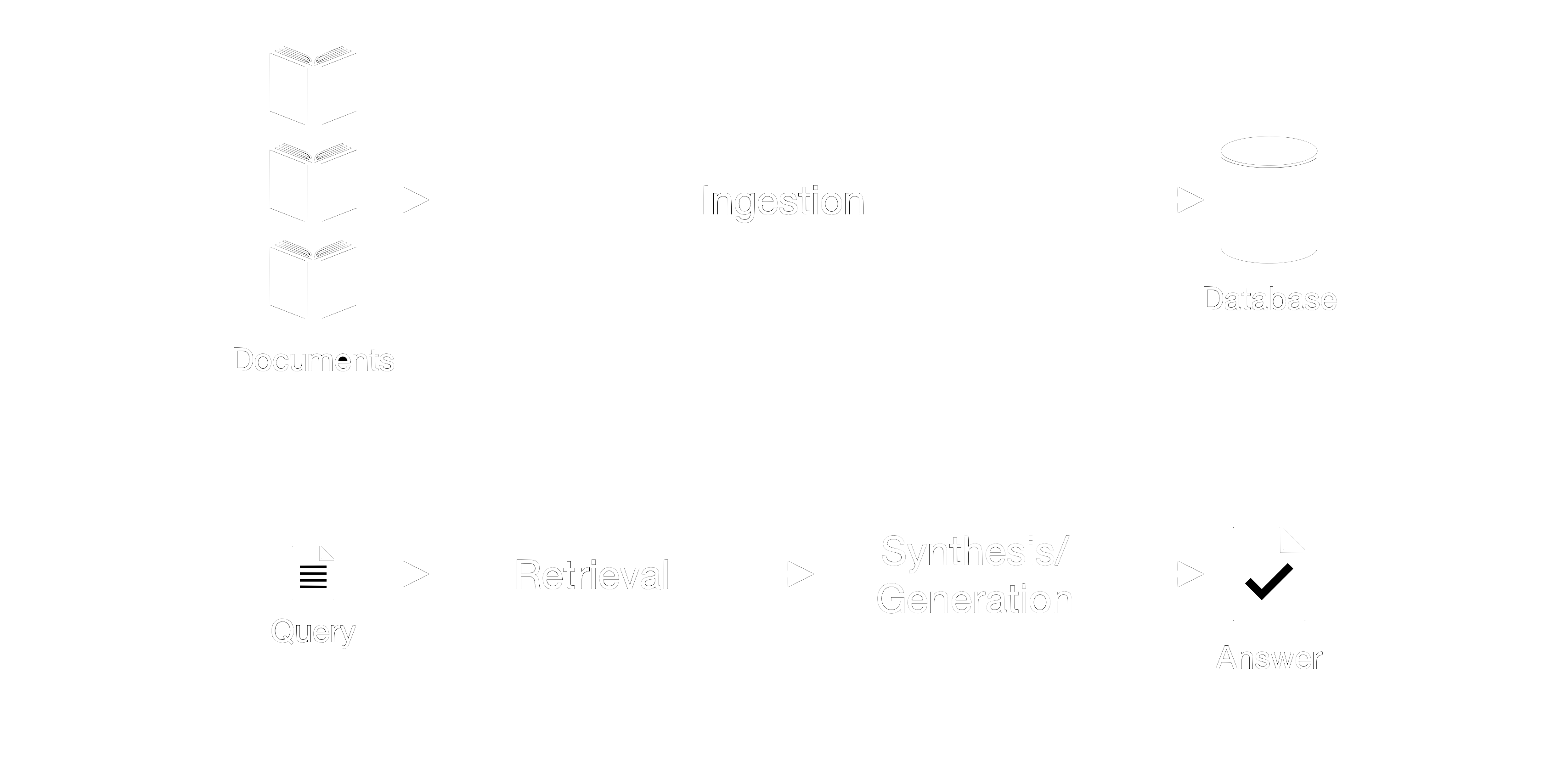
Figure 1: Overview of rag with ingestion, retrieval, and synthesis.
Ingestion Stage
The ingestion stage is the foundation of any RAG pipeline, and several factors can contribute to failures at this stage.
Firstly, the quality of the data fed into the system is crucial. If the data is not relevant to the types of questions you expect the system to handle, the generated answers will inevitably be of low quality. For instance, a dataset consisting of outdated or off-topic documents will not serve a user looking for current and specific information.
Another potential pitfall is the choice of embedding function. The embedding function needs to perform well for your specific data, as currently no specific embedding method dominates across tasks [1]. A poor embedding function choice can lead to inaccurate or irrelevant document retrievals. I like to check the Massive Text Embedding Benchmark (MTEB) Leaderboard [2] to find an embedding model.
Bias in the dataset itself can also cause significant issues. Inherent biases present in the data can skew the system’s responses. For example, a news corpus that primarily features articles from a single viewpoint will not provide a balanced perspective in its outputs. This bias is further compounded if the training data for the embedding model is biased. Such biases can creep in during the training phase due to the specific dataset used or decisions made during the model's training process.
Moreover, the process of chunking data can introduce failures. Poor chunking strategies, such as using chunks that are too small or too large, can result in loss of important information or dilution of relevant content with irrelevant text. For example, if chunks are too large, they may contain too much extraneous information, making it difficult for the retrieval component to extract the relevant parts.
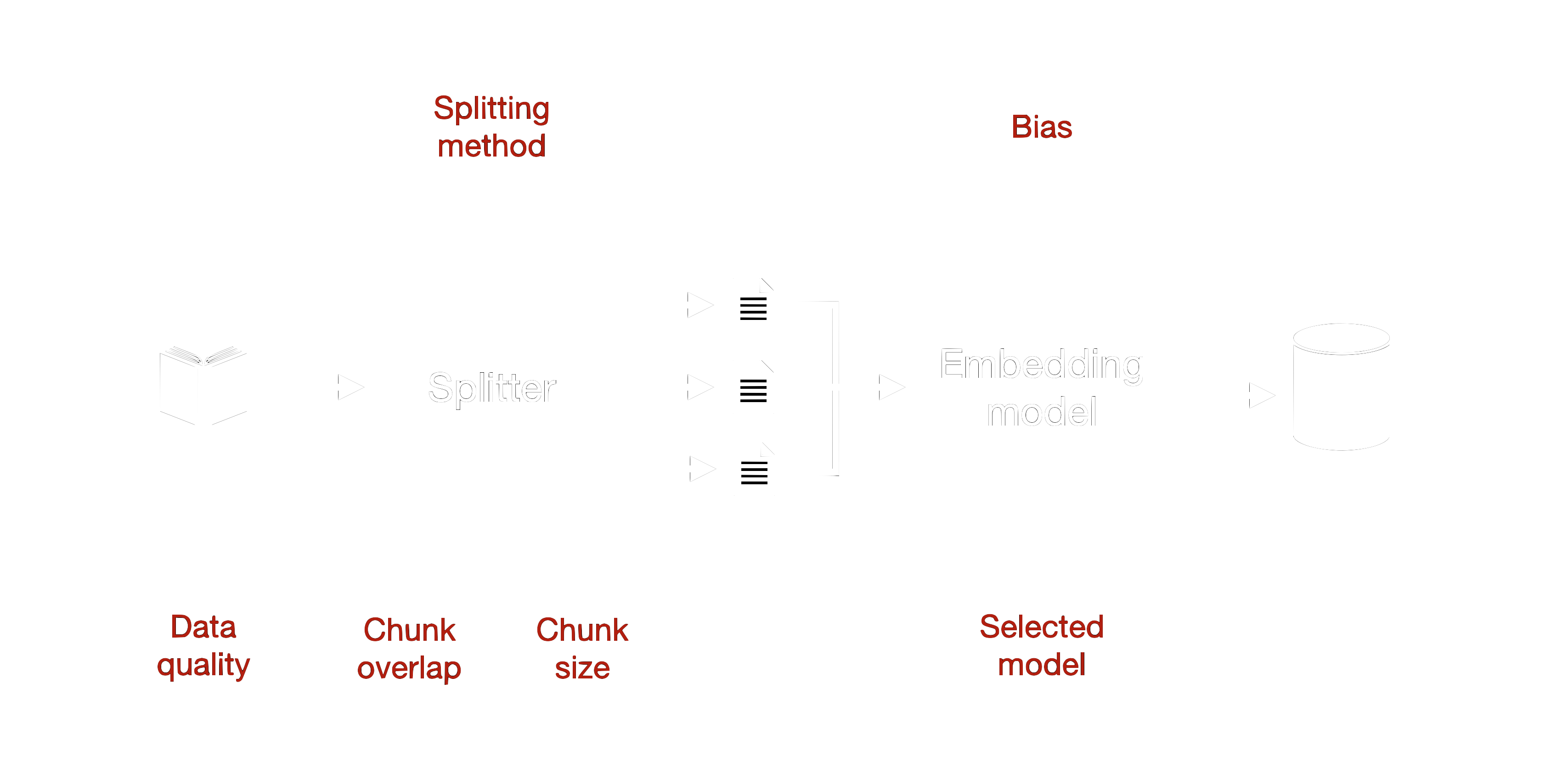
Figure 2: Ingestion splits a document into chunks, creates embeddings for each chunk, and adds them to the database. Selected failure influences are in red.
Retrieval Stage
The retrieval stage is where the system fetches relevant documents based on the user's query. This stage is critical, as the quality of the retrieved documents directly impacts the quality of the generated responses. Here are the detailed steps and some common failure modes that can occur during retrieval, which you can also see in figure 3.
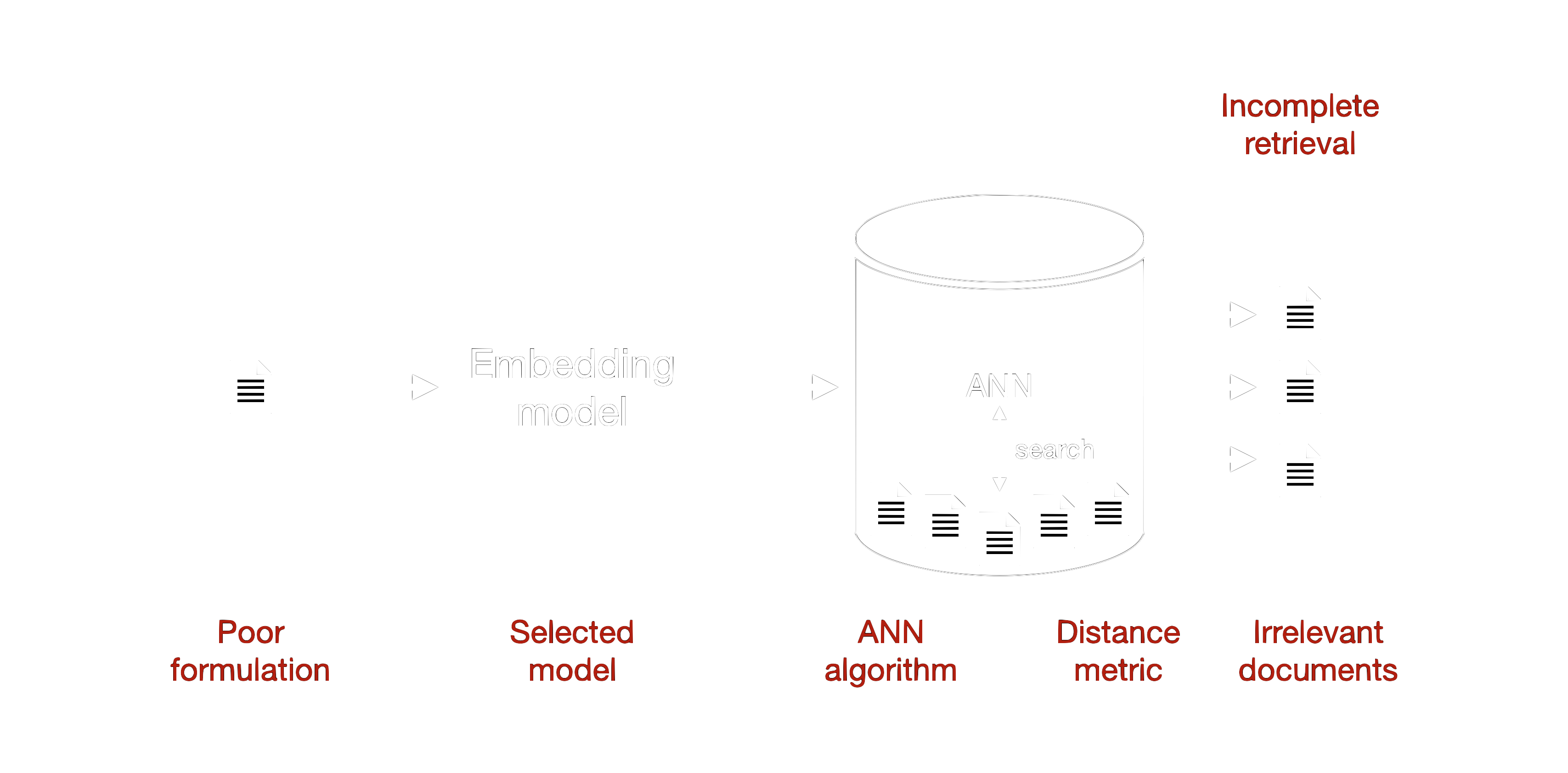
Figure 3: The stages of the retrieval process with selected failure modes in red.
Step 1: Query Formulation The process begins with the user's query. The system needs to accurately interpret the query to generate an effective search. Issues can arise from poor query formulation due to misunderstandings or ambiguity in the user's input.
Step 2: Embedding the Query The next step is to convert the user's query into an embedding using a pre-trained embedding model. This embedding represents the query in a high-dimensional vector space. The quality of the embedding is crucial, as it needs to capture the semantic meaning of the query accurately. As already mentioned in the previous section on ingestion, if the embedding model is not well-suited to the query's domain, the representation may be inadequate.
Step 3: Retrieval using ANN With the query now embedded, the system moves to the retrieval phase, utilizing Approximate Nearest Neighbors (ANN) algorithms. ANN is designed to quickly find the closest vectors (documents) to the query embedding based on a distance metric, such as cosine similarity or Euclidean distance. There are various ANN algorithms, falling into categories such as graph-based, hash-based, and more. All of them balance a trade-off between runtime and accuracy. For an overview of different ANN algorithms and their performance, you can refer to this website.
However, there are several potential pitfalls during this step. One common issue is the retrieval of irrelevant documents. This can happen if the query embedding does not accurately capture the semantic meaning of the query or if the chosen distance metric is not suitable for the type of data. Consequently, the ANN might return documents that are semantically similar but contextually irrelevant, leading to poor-quality responses.
Another frequent problem is incomplete retrieval. The ANN might miss documents that are crucial for a comprehensive answer if the dataset is not properly indexed or if the search parameters are too restrictive. This means that while some relevant documents are retrieved, others that might contain vital information are overlooked, resulting in incomplete or insufficient responses.
Ensuring the quality of this retrieval step is crucial, as it directly impacts the subsequent reranking and filtering stages. Addressing these issues involves fine-tuning the embedding model and distance metrics, as well as optimizing the indexing and search parameters to balance speed and accuracy.
Synthesis/Generation Stage
Once we have retrieved the suitable document chunks for our query, we move on to the synthesis stage, where a Large Language Model (LLM) generates the final response. This stage is crucial, as it transforms the retrieved information into a coherent and informative answer. However, several failure modes can occur during this phase, which we need to address.
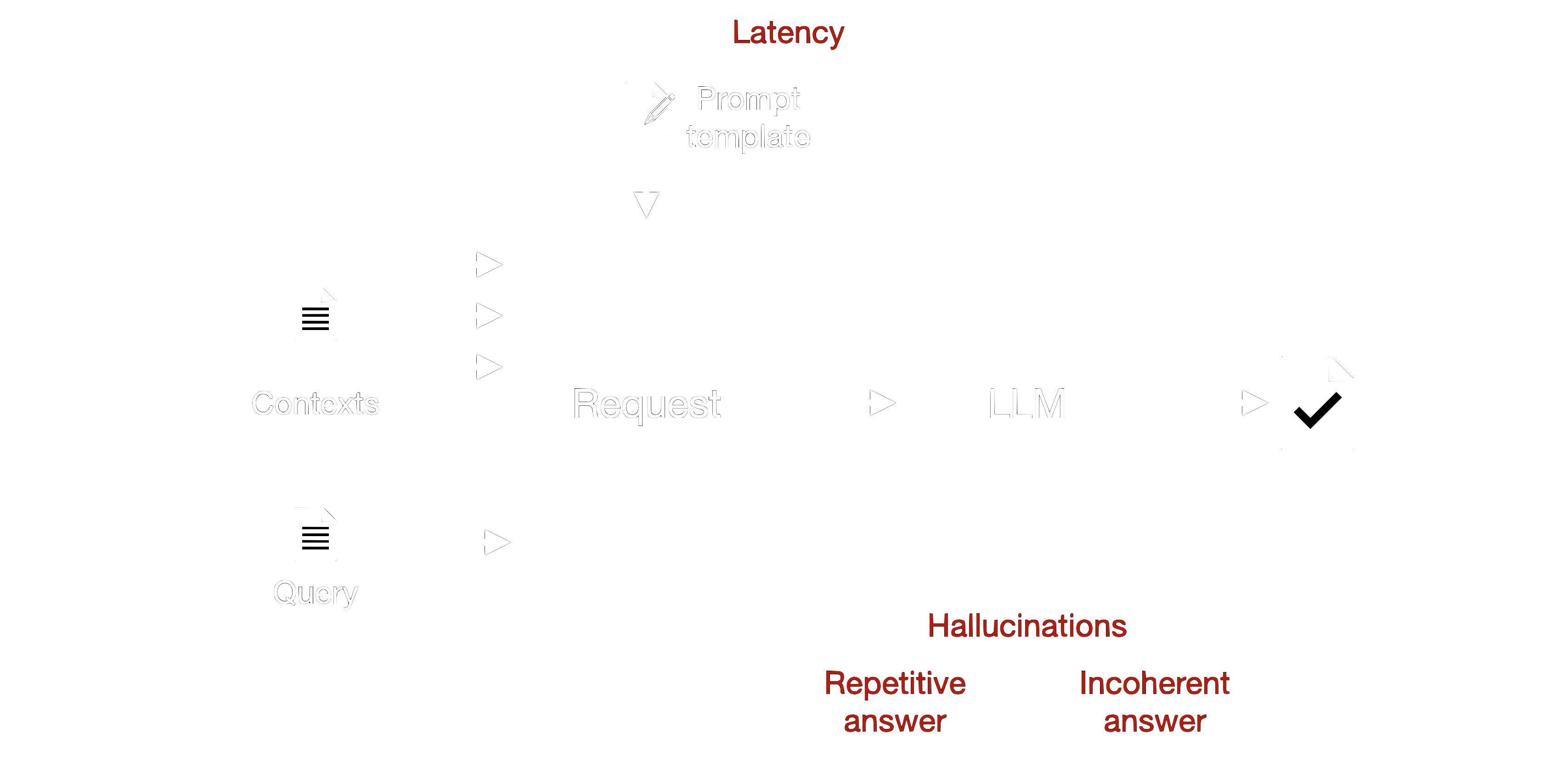
Figure 4: Failure modes in the synthesis stage. Latency effects all stages.
One common issue is when the generation model produces information not present in the retrieved documents or even fabricates facts. These hallucinations can lead to misleading or entirely incorrect responses, undermining the reliability of the system. Additionally, if the retrieved documents contain inaccuracies, the generated response might incorporate these errors, leading to factual inconsistencies. Ensuring the accuracy and reliability of the source documents is therefore essential.
Another significant problem arises when the retrieved documents are disjoint or unrelated. In such cases, the generation component may struggle to produce a coherent response, resulting in outputs that are confusing or difficult to understand. For instance, if the system retrieves documents with conflicting information or varying contexts, the generated response might lack a logical flow. This mismatch between retrieval and generation can reduce the overall effectiveness of the RAG system, as the generation component fails to leverage the full potential of the retrieved information. Additionally, the presence of distractors, which are completely irrelevant documents retrieved due to their semantic similarity, can cause the language model to produce false predictions. These distractors are particularly challenging to identify and debug. When a query is irrelevant to the existing data, the system might still return a set number of documents, leading to irrelevant or nonsensical responses. This highlights the importance of robust query handling and relevance checks.
The model may also generate repetitive content due to an over-reliance on certain retrieved documents or patterns learned during training. This repetition can lead to redundant and less engaging responses, diminishing the user experience. Furthermore, the generated response might sound awkward or unnatural due to limitations in the language model, affecting the overall readability and professionalism of the response.
The system may also experience delays due to the complexity of the retrieval and generation processes, especially with large datasets and complex models. These latency and performance issues can hinder user experience and make the system impractical for real-time applications. Scalability issues can arise if the system struggles to handle increasing data sizes or user queries due to inefficient retrieval algorithms or model limitations. This can lead to degraded performance and reduced reliability as the system grows.
Conclusion
In this post, we have explored the various ways a Retrieval-Augmented Generation (RAG) system can fail, examining each stage of the pipeline from ingestion to retrieval to synthesis/generation. Understanding these potential failure modes is crucial for anyone looking to build robust and reliable RAG systems.
By understanding these failure modes, we are better equipped to anticipate and mitigate issues in your RAG pipelines. This knowledge sets the stage for our next post, where we will delve into evaluation metrics and methodologies for assessing the performance of RAG systems. This will provide practical insights and tools to identify weaknesses and measure improvements in your pipelines.
References
[1] Niklas Muennighoff and Nouamane Tazi and Loïc Magne and Nils Reimers. (2023) MTEB: Massive Text Embedding Benchmark. https://arxiv.org/abs/2210.07316
[2] Massive Text Embedding Benchmark (MTEB) Leaderboard https://huggingface.co/spaces/mteb/leaderboard
[3] Nandan Thakur and Nils Reimers and Andreas Rücklé and Abhishek Srivastava and Iryna Gurevych. (2021) BEIR: A Heterogenous Benchmark for Zero-shot Evaluation of Information Retrieval Models. https://arxiv.org/abs/2104.08663
[4] Mengzhao Wang and Xiaoliang Xu and Qiang Yue and Yuxiang Wang. (2021) A Comprehensive Survey and Experimental Comparison of Graph-Based Approximate Nearest Neighbor Search. https://arxiv.org/abs/2101.12631
Loading comments...
Loading user status...