RAG Core library
Motivation
Retrieval-augmented generation (RAG) is useful if you want to ensure that a language model responds with factually accurate facts, and if you want to add or remove data quickly. To build a RAG application, a few components are required to work together. While there are frameworks out there, such as langchain, which allow you to build applications, RAGCore goes one step further. By supporting common integrations, you can build a RAG app with only a config file and a four basic methods: add, remove, list, query.
What is retrieval-augmented generation?
While large language models have showcased remarkable abilities in generating coherent text and answering questions, they occasionally fall short in providing accurate responses and lack up-to-date knowledge of recent events. To address these limitations, Retrieval-Augmented Generation (RAG) was introduced. This approach combines a large language model with a knowledge store, allowing it to access factual information. RAG empowers the system to draw on a database, giving users direct control over the knowledge base. Updating the knowledge is as simple as adding new information to the database, and the system can also ‘forget' easily by removing a document.
Components
A RAG system is composed of two distinct knowledge stores: a large language model, serving as parametric memory, and a database, functioning as non-parametric memory. In addition to these, the system features an embedding model. Users engage with the system by adding new documents, deleting documents, or querying it.
How it works
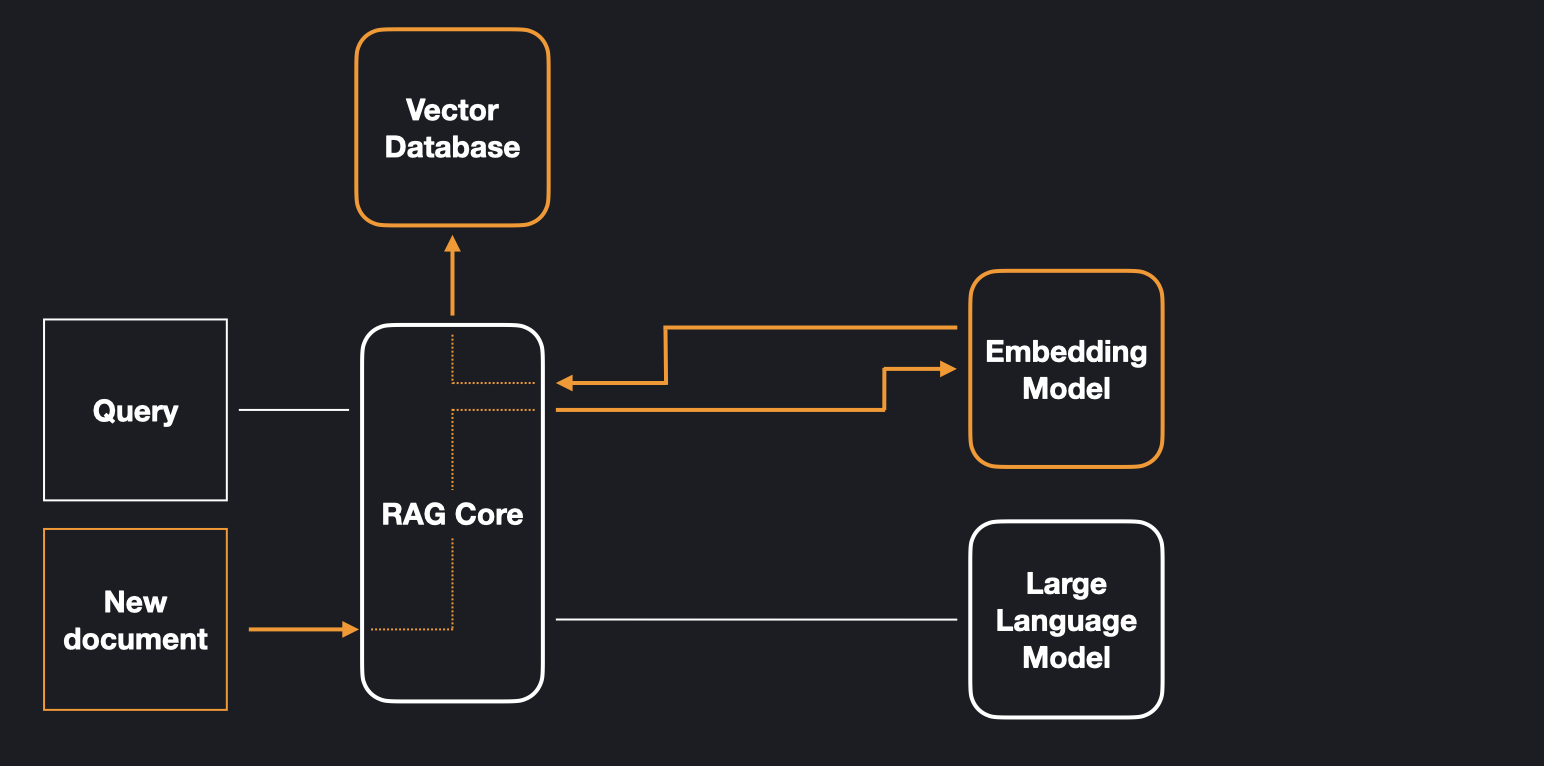
The database stores vector embeddings, which are representations of data. These embeddings are generated using an embedding model, a model which creates vector representations of fixed dimension for a given string input. Rather than adding a document as a whole, it is divided into overlapping chunks. This strategy allows the system to retrieve only the relevant pieces of information. The figure below highlights the components which are involved in adding a document and shows how the information flows between them.
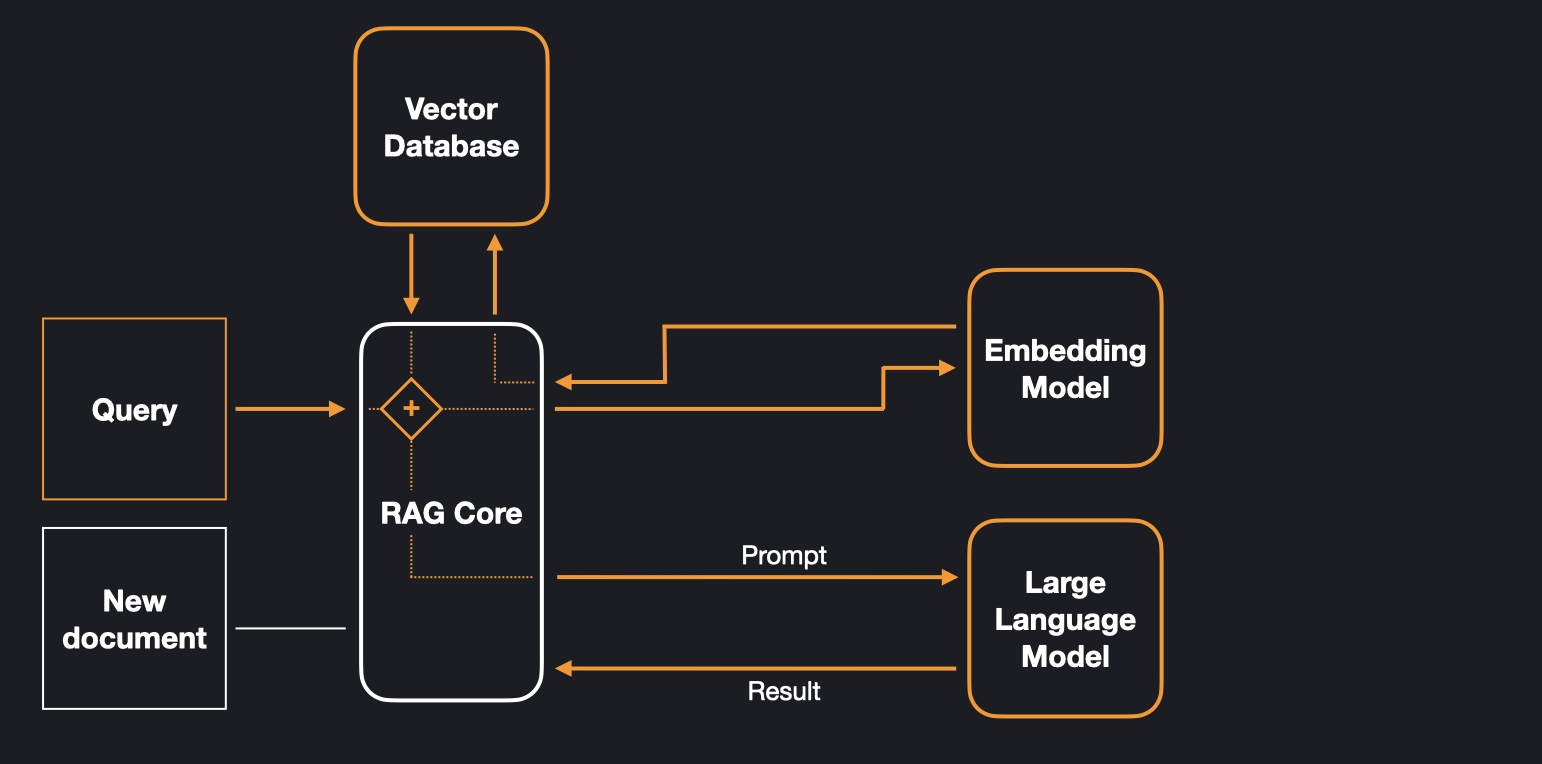
After a document is stored in the database, a query can be matched against it. This process involves creating an embedding vector from the query using the embedding model and identifying the most similar vectors in the database. Subsequently, the corresponding document chunks are retrieved from the database and forwarded to the large language model, as part of a prompt for generating a response. The model then combines the knowledge it has stored in its parameters with the relevant knowledge from the database to generate a response. The figure shows how the information flows between the components when the system is queried.
Creating your first RAG app
Let's create an application with a local Chroma database, the OpenAI LLM gpt-3.5-turbo, and the OpenAI embedding model text-embedding-ada-002.
First, make sure you have RAGCore installed by running
pip install ragcore
Then, since we are using OpenAI components, we first have to set the OpenAI API key as described here. For example, in bash run
export OPENAI_API_KEY=[your token]
Next, create a config file config.yaml in the root of your project with the following content:
database:
provider: "chroma"
number_search_results: 5
base_dir: "data/database"
splitter:
chunk_overlap: 256
chunk_size: 1024
embedding:
provider: "openai"
model: "text-embedding-ada-002"
llm:
provider: "openai"
model: "gpt-3.5-turbo"
Next, create a Python file for the application code. Your project should look similar to this example now:
myapp/
├── app.py
├── config.yaml
Finally, in the app.py file, we can implement our application using the components specified in the configuration. The following demonstrates the main methods:
from ragcore import RAGCore
USER = "01" # Optionally use a string to identify a user
app = RAGCore() # pass config=<path-to-config.yaml> if not in root
# Upload a document "My_Book.pdf"
app.add(path="My_Book.pdf", user=USER)
# Now you can ask questions
answer = app.query(query="What did the elk say?", user=USER)
print(answer.content)
# List the document's title and content on which the answer is based
for doc in answer.documents:
print(doc.title, " | ", doc.content)
# Get the user identifier
print(answer.user)
# List all documents in the database
print(rag_instance.get_titles(user=USER))
# You can delete by title
app.delete(title="My_Book", user=USER)
If your app should support more than one user with separate data for each, you can pass in a string user to identify a user.
And that's it! For more details on configuration options, please refer to the documentation.
References
Patrick Lewis et al. Retrieval-Augmented Generation for Knowledge-Intensive NLP Tasks. 2020 https://arxiv.org/pdf/2005.11401.pdf
Sebastian Riedel et al. Retrieval Augmented Generation: Streamlining the creation of intelligent natural language processing models. 2020 https://ai.meta.com/blog/retrieval-augmented-generation-streamlining-the-creation-of-intelligent-natural-language-processing-models/
Loading comments...
Loading user status...